[1]:
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
Tutorial B3: Spacing
predict + ersatz (multisubstitute) + predict
Although marginalization experiments can be invaluable in identifying the influence that one motif (or larger construct) has by itself, sometimes one wishes to investigate the influence that multiple motifs have and how this changes as spacings between them change. Specifically, one might want to see how model predictions change as two motifs are moved closer or further apart from each other. Given enough compute, one might even want to comprehensively look at how all pairs or sets of motifs influence predictions as they are spaced differently!
tangermeme implements this functionality in the space function, which is conceptually similar to the marginalize function except that it takes in a set of motifs and the respective spacing between them. Conceptually, the difference between marginalize and space is the difference between the substitute and the multisubstitute functions, where marginalize just substitutes in a given motif but space has to handle the bookkeeping of where precisely to substitute
motifs given a set of motifs of different lengths and their spacings.
Space
The basic functionality implemented in spacing experiments is the insertion of multiple motifs at a given spacing paired with predictions before and after the insertion. Accordingly, the signature is very similar to that of marginalize except that a list of motifs are passed in alongside either one or more values corresponding to the spacing. Predictions are made before and after the motifs are inserted and returned.
Let’s show an example using the Beluga/DeepSEA model.
[2]:
import torch
from model import Beluga
model = Beluga()
model.load_state_dict(torch.load("deepsea.beluga.torch"))
[2]:
<All keys matched successfully>
Then, we can generate some random sequence. Just like when running marginalizations, the choice of background sequence is important and simply using uniform random sequence (like we do here) will likely be suboptimal. However, it is a simple background to implement, so we’ll use it here.
[3]:
from tangermeme.utils import random_one_hot
X = random_one_hot((100, 4, 2000)).type(torch.float32) # Generate 100 random sequences to marginalize over
Now, we just need a motif to add in. We can start off with adding in two AP-1 motifs. We also need to pass in the spacing between these motifs. Because this function allows you to pass in any number of motifs and investigate any number of spacings, spacing must be an array-like of non-negative integers of shape (n_spacings, n_motifs-1) where entry i,j refers to the spacing in the i-th spacing to try out between motifs of rank j and j+1. spacing does not have to
explicitly be a torch.tensor object, but has to be able to be cast into one with the described dimensions. Here, we want to just try out one spacing and there are only two motifs, so we’ll just pass in a tensor with a single value.
[4]:
from tangermeme.space import space
y_before, y_after = space(model, X, ["GTGACTCATC", "GTGACTCATC"], spacing=[[10]], device='cpu')
y_before.shape, y_after.shape
[4]:
(torch.Size([100, 1, 2002]), torch.Size([100, 1, 2002]))
This will add two motifs in with a spacing of 10 between them. By default, the range from the start of the first motif to the end of the last motif (including the spacing between the motifs) will be substituted into the center of the sequence. Characters that reside in the spacing between the motifs are left as-is. If start is provided, the first character of the first motif is inserted at that position and the rest of the sequence proceeds from there.
First, we can check that adding in the AP-1 motifs increased the predicted value for a task involving an AP-1 factor.
[5]:
y_before.mean(axis=0)[0, 267], y_after.mean(axis=0)[0, 267]
[5]:
(tensor(-3.6887), tensor(-0.5963))
Looks like the logit increased quite a bit, as we might expect.
Next, we can look at how changing the spacing between these motifs changes the predicted value to see if there is some sort of synergeistic effect between the two motifs. Since we want to run many spacing experiments (one per potential spacing), we will pass in a tensor of spacings of shape (50, 1) – 50 because we want to run 50 experiments, and 1 because there is only a pair of motifs.
[6]:
y_before, y_after = space(model, X, ["GTGACTCATC", "GTGACTCATC"], spacing=torch.arange(50)[:, None], device='cpu')
y_before.shape, y_after.shape
[6]:
(torch.Size([100, 50, 2002]), torch.Size([100, 50, 2002]))
[7]:
from matplotlib import pyplot as plt
import seaborn; seaborn.set_style('whitegrid')
plt.figure(figsize=(6, 4))
plt.plot(y_after.mean(dim=0)[:, 267])
plt.xlabel("Spacing Between Motifs", fontsize=10)
plt.ylabel("Predicted Logit")
plt.tight_layout()
plt.show()

It looks like there may be some sort of synergy between the two motifs. As the motifs get further apart, the predicted logit from the model goes down. But, there also seems to be some sort of cyclic aspect to it where every few basepairs the predicted probability increases before then continuing to decrease. This is potentially due to the shape of the DNA playing a role in binding – where every half turn (around 6-7 bp) there is a complementary effect.
If we have more than two motifs we can just pass in a longer list that includes the spacings between both adjacent pairs of motifs.
[8]:
y_before, y_after = space(model, X, ["GTGACTCATC", "GTGACTCATC", "GTGACTCATC"], spacing=[[10, 10]], device='cpu')
y_before.mean(axis=0)[0, 267], y_after.mean(axis=0)[0, 267]
[8]:
(tensor(-3.6887), tensor(0.7865))
Looks like having a third motif does increase binding by a little bit.
This formulation for spacing means that we can easily change the spacing between different motifs.
[9]:
y_before, y_after = space(model, X, ["GTGACTCATC", "GTGACTCATC", "GTGACTCATC"], spacing=[[4, 10]], device='cpu')
y_before.mean(axis=0)[0, 267], y_after.mean(axis=0)[0, 267]
[9]:
(tensor(-3.6887), tensor(1.0361))
Naturally, the motifs do not have to be the same. If you want to investigate the role that different motifs have across spacings, this function is perfect.
[10]:
y_before, y_after = space(model, X, ["GTGACTCATC", "ACATTG", "ATAGA"], spacing=[[4, 10]], device='cpu')
y_before.mean(axis=0)[0, 267], y_after.mean(axis=0)[0, 267]
[10]:
(tensor(-3.6887), tensor(-2.2331))
We can see that only adding in one AP-1 motif, and two gibberish motifs, causes the predictions to only increase modestly. This modest increase makes sense because the previous instances had multiple copies of that motif. We can confirm that there isn’t some weird effect being learned by checking the predictions as we change the spacing between the AP-1 motif and the other pseudomotifs there.
[11]:
spacing = torch.zeros(50, 2)
spacing[:, 0] = torch.arange(50)
spacing[:, 1] = 10
y_before, y_after = space(model, X, ["CTCAGTGATG", "ACATTG", "ATAGA"], spacing=spacing, device='cpu')
[12]:
plt.figure(figsize=(6, 4))
plt.plot(y_after.mean(dim=0)[:, 267])
plt.xlabel("Spacing Between Motifs", fontsize=10)
plt.ylabel("Predicted Logit")
plt.tight_layout()
plt.show()
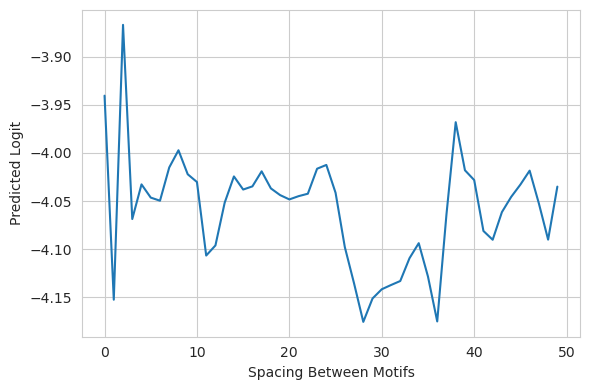
We can see that, although there is some wiggling in the prediction as the distance between the first two motifs increases, the magnitude does not significantly change overall and the trendline is basically flat. This confirms that there is not always a synergistic effect between motifs.